使用其他CLIP模型
如果对默认的ChineseCLIP模型在以文搜图时的准确率不满意,可以使用本教程中的方法来使用其他的CLIP模型;
devfox101/mt-photos-ml镜像,基于 immich-machine-learning:v2.7.5 镜像构建,为MT Photos 提供CLIP识别、文本识别、人脸识别的API;
devfox101/mt-photos-ml镜像内默认使用的模型;
- CLIP识别模型使用
XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k- 这个模型相较于官方镜像中的 ChineseCLIP 模型,解决了不认识颜色的问题
- OCR识别模型使用
PP-OCRv5_mobile - 人脸识别模型使用
buffalo_l
相关GitHub代码仓库地址:
https://github.com/dev-fox-101/mt-photos-ml
docker镜像说明
DockerHub镜像仓库地址: https://hub.docker.com/r/devfox101/mt-photos-ml
镜像Tags说明:
devfox101/mt-photos-ml:v2.7.5:x86架构的CPU处理识别任务,所有Intel、AMD 处理器都可以运行这个镜像devfox101/mt-photos-ml:v2.7.5-arm:arm64架构的CPU处理识别任务, arm架构的nas、以及m系列芯片的mac可以运行这个镜像devfox101/mt-photos-ml:v2.7.5-cuda:Nvidia显卡使用GPU处理识别任务,需要Nvidia显卡devfox101/mt-photos-ml:v2.7.5-openvino:Intel CPU使用OpenVINO调用核显或者独立显卡处理识别任务devfox101/mt-photos-ml:v2.7.5-rocm:AMD显卡使用GPU处理识别任务,需要AMD显卡devfox101/mt-photos-ml:v2.7.5-rknn:Rockchip使用GPU处理识别任务,支持RK3566, RK3568, RK3576 and RK3588devfox101/mt-photos-ml:v2.7.5-armnn:ARM Mali GPU使用GPU处理识别任务
支持配置的环境变量
- API_AUTH_KEY:API认证密钥,用于保护API接口,防止被恶意访问, 默认值为:
mt_photos_ai_extra - OCR_MODEL_NAME:OCR模型名称,用于指定使用哪个OCR模型进行文字识别,默认值为:
PP-OCRv5_mobile - CLIP_VISUAL_MODEL_NAME:CLIP模型名称,用于指定使用哪个CLIP模型进行图片识别,默认值为:
XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k - CLIP_TEXTUAL_MODEL_NAME:CLIP模型名称,用于指定使用哪个CLIP模型进行文本处理,默认值为:
XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k - FACE_DETECTION_MODEL_NAME:人脸检测模型名称,用于指定使用哪个模型进行人脸检测,默认值为:
buffalo_l - FACE_RECOGNITION_MODEL_NAME:人脸特征提取模型名称,用于指定使用哪个模型进行人脸特征提取,默认值为:
buffalo_l - FACE_MIN_SCORE:人脸检测最小置信度,默认值为:
0.65
CLIP模型选择
XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k 和 XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
对于中文特有的一些元素搜索效果相较与nllb模型更好,比如:春节、鞭炮之类; 因此使用了XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k 作为默认值;
支持的CLIP模型:
| Model | Memory (MiB) | Execution Time (ms) | Recall (%) | Pareto Optimal |
|---|---|---|---|---|
| nllb-clip-large-siglip__v1 | 4226 | 75.05 | 79.7 | ✅ |
| nllb-clip-large-siglip__mrl | 4248 | 75.44 | 78.94 | ❌ |
| XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k | 4014 | 39.14 | 75.22 | ✅ |
| nllb-clip-base-siglip__v1 | 4675 | 15.17 | 74.8 | ✅ |
| nllb-clip-base-siglip__mrl | 4696 | 16.95 | 73.91 | ❌ |
| ViT-gopt-16-SigLIP2-384__webli | 6585 | 146.84 | 72.8 | ❌ |
| ViT-SO400M-16-SigLIP2-512__webli | 4050 | 107.67 | 72.77 | ❌ |
| ViT-SO400M-14-SigLIP2-378__webli | 3940 | 72.25 | 72.41 | ✅ |
| ViT-SO400M-16-SigLIP2-384__webli | 3854 | 56.57 | 72.36 | ✅ |
| ViT-gopt-16-SigLIP2-256__webli | 6475 | 64.51 | 71.59 | ❌ |
| ViT-L-16-SigLIP2-512__webli | 3358 | 92.59 | 71.37 | ✅ |
| ViT-SO400M-16-SigLIP2-256__webli | 3611 | 27.84 | 71.3 | ✅ |
| ViT-L-16-SigLIP2-384__webli | 3057 | 51.7 | 71.11 | ✅ |
| ViT-SO400M-14-SigLIP2__webli | 3622 | 27.63 | 70.95 | ✅ |
| ViT-L-16-SigLIP2-256__webli | 2830 | 23.77 | 70.51 | ✅ |
| ViT-B-16-SigLIP-i18n-256__webli | 3029 | 6.87 | 67.48 | ✅ |
| ViT-B-16-SigLIP2__webli | 3038 | 5.81 | 66.84 | ✅ |
| XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k | 3030 | 3.2 | 65.7 | ✅ |
| ViT-B-32-SigLIP2-256__webli | 3061 | 3.31 | 63.38 | ❌ |
指定CLIP模型的方法 (可选)
提示:镜像默认使用的CLIP模型为:
XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k,已足够满足大部分关键词的以文搜图需求;建议先使用默认的模型识别后看下效果;
如果想要自定义容器使用的CLIP模型,以 XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k 举例;
那么需要在创建容器时,增加这2个环境变量: -e CLIP_VISUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k -e CLIP_TEXTUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
这样可以指定CLIP模型使用XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
完整的docker run命令示例
docker run -i -p 8060:3003 -e API_AUTH_KEY=mt_photos_ai_extra -e CLIP_VISUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k -e CLIP_TEXTUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k -v /mnt/mt-photos/ml-cache:/cache --name mt-photos-ml --restart="unless-stopped" devfox101/mt-photos-ml:v2.7.5
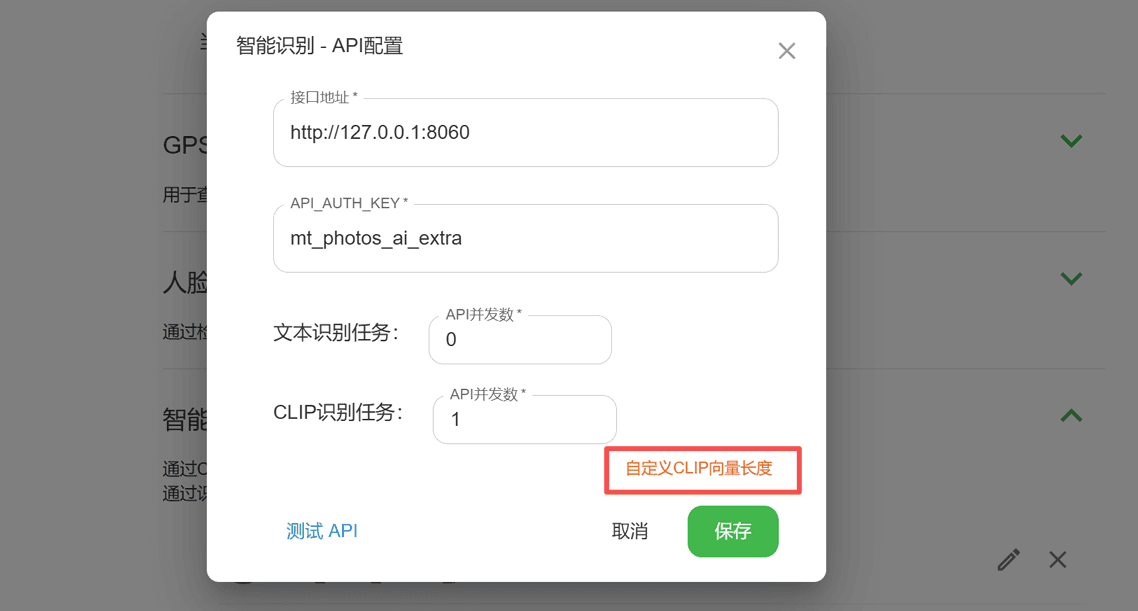
自定义CLIP模型返回的向量长度 (可选)
默认CLIP模型返回的向量长度为512,如果使用的模型返回的向量长度不是512,需要在 智能识别API配置那边通过 自定义CLIP向量长度 来修改;
比如以下CLIP模型返回的向量长度就不是512:
- 'XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k': { dimSize: 1024 }
- 'nllb-clip-base-siglip__mrl': { dimSize: 768 }
- 'nllb-clip-base-siglip__v1': { dimSize: 768 }
- 'nllb-clip-large-siglip__mrl': { dimSize: 1152 }
- 'nllb-clip-large-siglip__v1': { dimSize: 1152 }
注意: 如果使用的模型返回的向量长度不是512,需要自定义CLIP向量长度
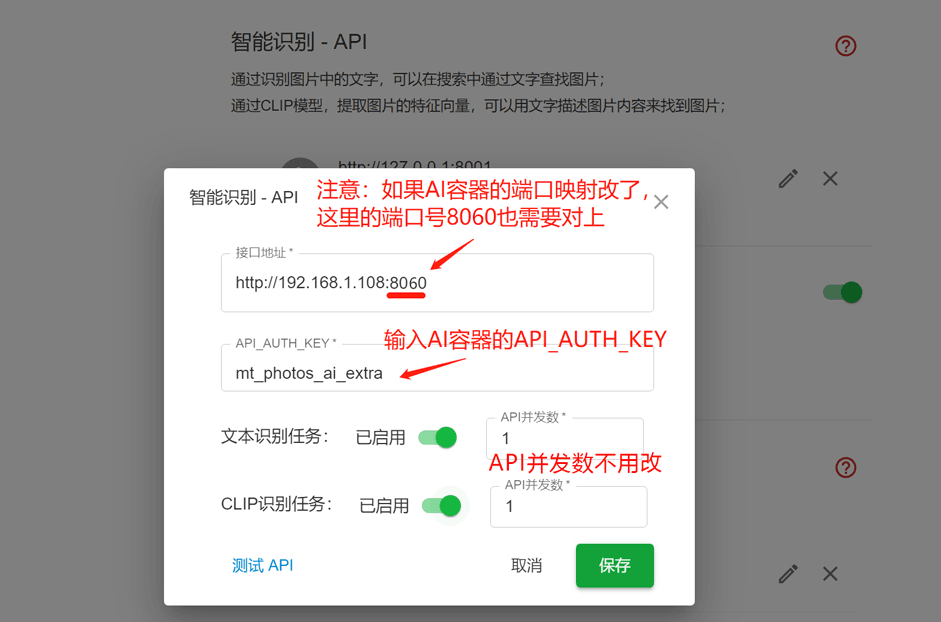
下载镜像、创建docker容器
注意: 需要有目录映射 /cache,它用于存储各个识别模型的模型文件
注意: 端口映射是-p 8060:3003,也就是容器内服务端的端口为3003
x86 CPU:
docker pull devfox101/mt-photos-ml:v2.7.5
docker run -i -p 8060:3003 -e API_AUTH_KEY=mt_photos_ai_extra -v /mnt/mt-photos/ml-cache:/cache --name mt-photos-ml --restart="unless-stopped" devfox101/mt-photos-ml:v2.7.5
arm64 CPU:
docker pull devfox101/mt-photos-ml:v2.7.5-arm
docker run -i -p 8060:3003 -e API_AUTH_KEY=mt_photos_ai_extra -v /mnt/mt-photos/ml-cache:/cache --name mt-photos-ml --restart="unless-stopped" devfox101/mt-photos-ml:v2.7.5-arm
cuda加速 :
docker pull devfox101/mt-photos-ml:v2.7.5-cuda
docker run --gpus all -i -p 8060:3003 -e API_AUTH_KEY=mt_photos_ai_extra -v /mnt/mt-photos/ml-cache:/cache --name mt-photos-ml --restart="unless-stopped" devfox101/mt-photos-ml:v2.7.5-cuda
openvino加速 :
docker pull devfox101/mt-photos-ml:v2.7.5-openvino
docker run -i -p 8060:3003 -e API_AUTH_KEY=mt_photos_ai_extra --device /dev/dri:/dev/dri -v /mnt/mt-photos/ml-cache:/cache --name mt-photos-ml --restart="unless-stopped" devfox101/mt-photos-ml:v2.7.5-openvino
无法下载镜像的解决方法:https://mtmt.tech/docs/advanced/network
设置下载模型文件的镜像源
在创建容器时,可以给容器增加这个环境变量来指定下载模型的镜像源,来提升下载模型的速度:
-e HF_ENDPOINT=https://hf-mirror.com
yaml模板
完整的yaml模板:
version: "3"
services:
mtphotos:
image: registry.cn-hangzhou.aliyuncs.com/mtphotos/mt-photos:latest
container_name: mtphotos
restart: always
ports:
- 8063:8063
volumes:
- /volume1/docker/mt_photos/config:/config
- /volume1/photos/mt_photos_upload:/upload
- /volume1/xxx/其他需要映射的目录:/photos #提示:下面这2行是其他需要映射给容器的文件夹,如果没有可以删除这2行
- /volume1/xxx/xxx/share_photos:/share_photos #提示:目录映射必须要用 : 分隔开,左边填写nas中的文件路径, 右边添加映射到容器内的路径, 也就是添加图库时选择的文件夹路径
#- /etc/localtime:/etc/localtime:ro # 如果服务器时区不是UTC+8,需要添加这行来覆盖镜像内部的时区
environment:
- TZ=Asia/Shanghai # 指定容器内的时区
- LANG=C.UTF-8
depends_on:
- mtphotos_ai
# =======================
# 以上部分不需要修改,保持原来的配置不变
# 修改下面这部分:
# =======================
mtphotos_ai:
image: devfox101/mt-photos-ml:v2.7.5 # tag v2.7.5可以根据运行的环境替换为 v2.7.5-arm 、 v2.7.5-cuda 、 v2.7.5-openvino
# runtime: nvidia # 如果需要使用cuda,就取消这一行的注释
container_name: mtphotos_ai
restart: always
# devices:
# - "/dev/dri:/dev/dri" #如果需要使用intel核显,就取消这一行和上一行的注释
ports:
- 8060:3003
volumes:
- /volume1/docker/mt_photos/ml-cache:/cache #用来存放各种识别模型的文件
environment:
- API_AUTH_KEY=mt_photos_ai_extra
#- HF_ENDPOINT=https://hf-mirror.com #如果下载模型失败,可以尝试取消这一行的注释,使用hf的镜像地址下载模型
# 下面2行为自定义CLIP模型的示例
#- CLIP_VISUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
#- CLIP_TEXTUAL_MODEL_NAME=XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
添加api使用
返回MT Photos的系统设置中,在智能识别API 和 人脸识别API配置中;
智能识别API配置
接口地址 填写 http://[nas的ip]:8060
API_AUTH_KEY 填写 mt_photos_ai_extra (这是默认值,如果上一步有修改过,用修改过的值)
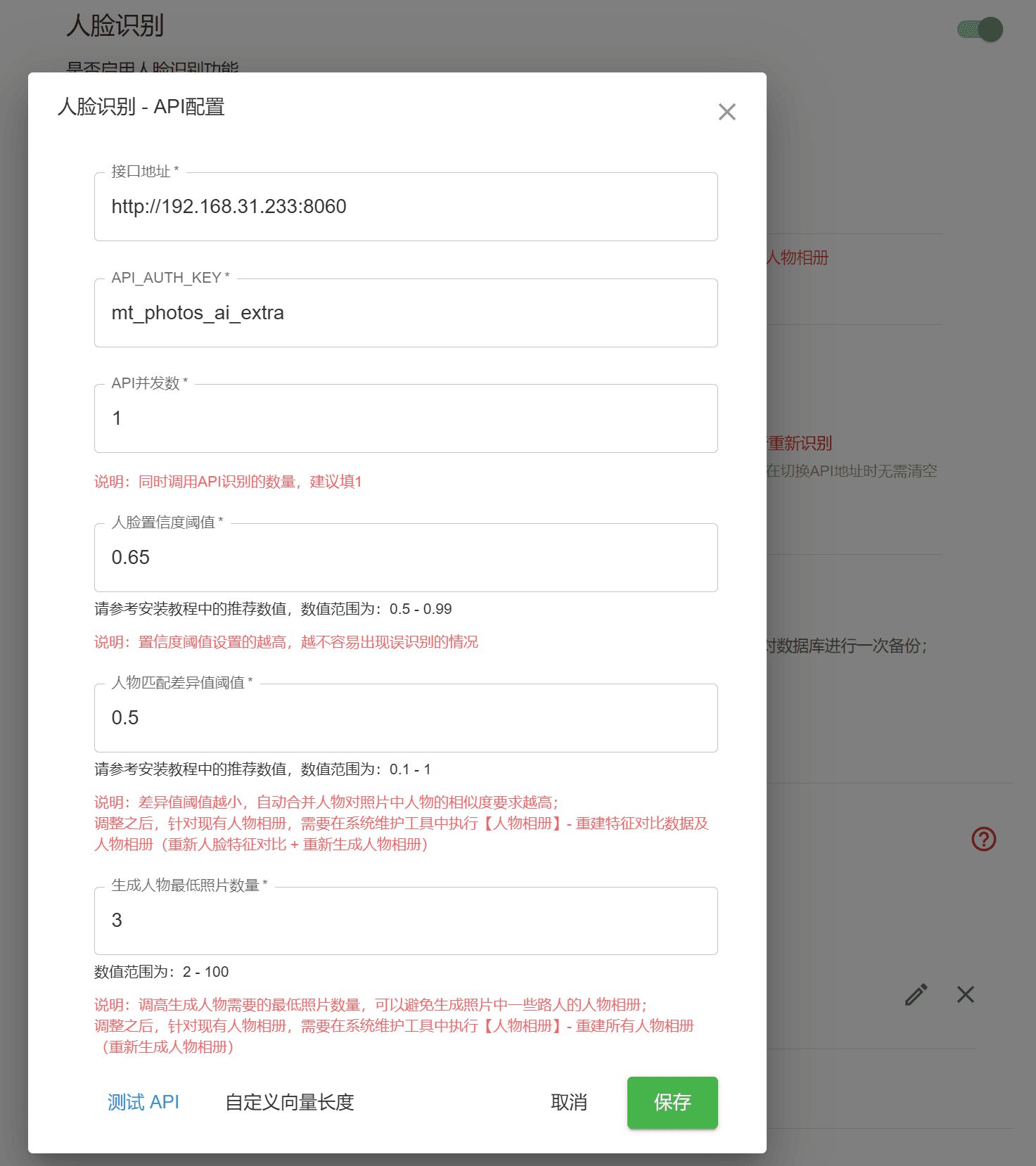
人脸识别API配置
接口地址 填写 http://[nas的ip]:8060
API_AUTH_KEY 填写 mt_photos_ai_extra (这是默认值,如果上一步有修改过,用修改过的值)
人脸置信度阈值设置 填 0.65
人脸匹配差异度阈值 填 0.5
不需要点击自定义向量长度,使用默认的512即可;
提前下载模型文件
提示: 第一次调用api时,容器内会下载模型到容器内的 /cache 文件夹内,因此根据网络环境,需要等待一段时间才能识别;
可以提前下载这个zip文件,然后解压到/volume1/docker/mt_photos/ml-cache(也就是映射/cache的那个文件夹)内;注意最终 ml-cache 文件夹内有 clip、facial-recognition、ocr 这3个文件夹,注意解压文件后目录不要放错;
镜像默认模型文件
https://github.com/dev-fox-101/mt-photos-ml/releases/download/v2.5.6/ml-cache.zip
以/volume1/docker/mt_photos/ml-cache 文件夹,内部文件层级举例:
.
└── ml-cache
├── clip
│ └── XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k
│ ├── README.md
│ ├── config.json
│ ├── models--immich-app--XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k
│ │ └── refs
│ │ └── main
│ ├── textual
│ │ ├── model.onnx
│ │ ├── sentencepiece.bpe.model
│ │ ├── special_tokens_map.json
│ │ ├── tokenizer.json
│ │ └── tokenizer_config.json
│ └── visual
│ ├── model.onnx
│ └── preprocess_cfg.json
├── facial-recognition
│ └── buffalo_l
│ ├── README.md
│ ├── detection
│ │ ├── model.onnx
│ │ └── rknpu
│ │ ├── rk3566
│ │ │ └── model.rknn
│ │ ├── rk3568
│ │ │ └── model.rknn
│ │ ├── rk3576
│ │ │ └── model.rknn
│ │ └── rk3588
│ │ └── model.rknn
│ ├── models--immich-app--buffalo_l
│ │ └── refs
│ │ └── main
│ └── recognition
│ ├── model.onnx
│ └── rknpu
│ ├── rk3566
│ │ └── model.rknn
│ ├── rk3568
│ │ └── model.rknn
│ ├── rk3576
│ │ └── model.rknn
│ └── rk3588
│ └── model.rknn
└── ocr
└── PP-OCRv5_mobile
├── detection
│ └── model.onnx
└── recognition
└── model.onnx
27 directories, 24 files
XLM-Roberta-Large-ViT-H-14模型文件
如果需要使用 XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k 模型,但是容器内下载文件失败,可以点击下面的链接
https://github.com/dev-fox-101/mt-photos-ml/releases/tag/v2.5.6_modal
下载这5个文件;
XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.001
XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.002
XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.003
XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.004
XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.005
然后右键 XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.001 解压到 ml-cache/clip 内,然后重启容器即可正常调用api;
解压后文件的目录层级应该是下面这样的:
.
└── ml-cache
├── clip
│ ├── XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k
│ │ ├── README.md
│ │ ├── config.json
│ │ ├── models--immich-app--XLM-Roberta-Base-ViT-B-32__laion5b_s13b_b90k
│ │ ├── textual //这里省略了下级的文件
│ │ └── visual //这里省略了下级的文件
│ ├── XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
│ │ ├── README.md
│ │ ├── config.json
│ │ ├── models--immich-app--XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
│ │ ├── textual //这里省略了下级的文件
│ │ └── visual //这里省略了下级的文件
│ └── XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k.zip.tmp
├── facial-recognition
│ └── buffalo_l
│ ├── README.md
│ ├── detection
│ ├── models--immich-app--buffalo_l
│ └── recognition
└── ocr
└── PP-OCRv5_mobile
├── detection
└── recognition
清除旧数据+重新识别
CLIP
如果之前已经使用mtphotos/mt-photos-ai处理了 CLIP识别;
由于模型的变化,需要清除旧数据后重新识别,操作步骤为:
- 1、关闭CLIP识别,并且确认当前没有在执行的后台任务
- 2、在系统维护工具中,执行 【CLIP识别】- 清空识别结果,然后重新识别所有照片 任务
- 3、等待后台任务中 重置CLIP识别状态中 任务完成后,再开启CLIP识别
- 4、等待 CLIP识别识别完成
文本识别
文本识别 不需要清空旧数据+重新识别;
人脸识别
如果之前使用的是 devfox101/mt-photos-insightface-unofficial 或者 devfox101/mt-photos-ai 镜像,并且人脸识别模型是默认的 buffalo_l 模型,那么不需要清空旧数据+重新识别;
如果之前使用的不是insightface相关的镜像, 可以按这个步骤清空数据重新识别:
-
1、先关闭人脸识别开关,确认没有正在运行的人脸识别任务;
-
2、在工具=>系统维护工具 中执行 【人物相册】- 重建全部数据。建议在清空识别结果前,对数据库进行一次备份;
-
3、等待后台任务中数据清除任务完成之后,再切换内置识别模型或人脸识别API
-
4、填写API配置,注意:当换了人脸识别的API后,请检查人脸置信度和匹配差异值阈值是否为安装教程中推荐的值
-
5、最后打开人脸识别开关,查看后台任务信息
